Data Scientist or AI Developer: That's the question
Autor: Klaus Puchner (Program Manager AI & Team Lead)
Vorstellung der Rolle Data Scientist / AI Developer
Im letzten Teil unserer Mini Blog Serie widmen wir uns der letzten, bisher noch nicht vorgestellten Rolle: dem Data Scientist. Oft als “Sexiest Job of the 21st Century” in den Medien betitelt, spielt der Data Scientist tatsächlich eine wesentliche Rolle, wenn es darum geht aus Daten einen Mehrwert zu generieren. Dies trifft auch vollends in unseren Projekten zu. In der Praxis gilt es jedoch auch noch andere Herausforderungen zu meistern, um aus einem tollen Modell ein erfolgreiches AI Produkt zu machen, das auch in der Praxis in bestehenden Geschäftsprozessen integrierbar ist.
Welche Aufgaben hat ein Data Scientist im AI Team?
In den Anfängen unseres Teams hatten auch wir noch ein sehr klassisches Rollenbild eines Data Scientist im Fokus. Dieses beinhaltete primär die Bewältigung der Aufgaben Datenbeschaffung, EDA (Explorative Daten Analyse), Feature Engineering sowie Modell Auswahl, Training, gegebenenfalls Hyperparameter Tuning und Evaluierung mit einer Data Science Sprache der Wahl (R oder Python).
Ein Data Scientist hat bei uns im AI Team die Möglichkeit, ohne Einschränkungen, die für die Aufgabenstellung und der damit einhergehenden Rahmenbedingungen beste Lösung einzusetzen. Sind beispielsweise verhältnismäßig wenig Daten verfügbar kann er auf klassische Machine Learning Modelle zurückgreifen (in einem Projekt haben wir beispielsweise über 100 Modelle getestet). Ist eine große Datenmenge vorhanden kann auch Deep Learning eingesetzt werden.
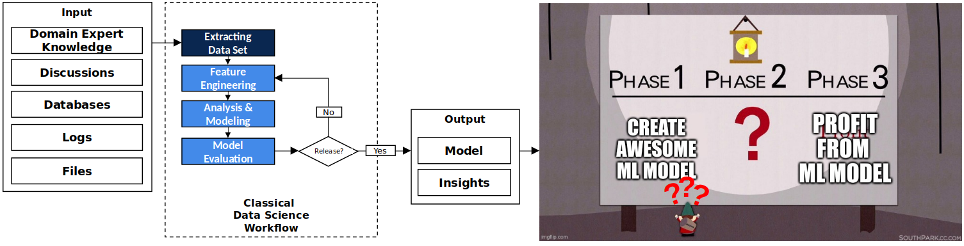
Die Fähigkeit, ein AI Modell in einen geschäftlichen Nutzen umzuwandeln, ist eine entscheidende Herausforderung.
Im Zuge unserer ersten beiden Projekte wurde uns schnell bewusst, dass es mehr als nur ein Modell mit guter Predictive Power braucht. Wie wir mit dieser Erkenntnis umgehen, stellen wir weiter unten vor.
Wie sorgt der Data Scientist dafür, dass sein Modell auch in der Praxis ankommt?
Wie schon angemerkt generiert ein Modell erst dann einen Mehrwert in der Praxis, wenn es auch tatsächlich in den Geschäftsprozessen eingesetzt wird. Ein Modell muss also auch mit wenig Integrationsaufwand in bereits bestehenden Systemarchitekturen und Softwareprodukten im Unternehmen nutzbar gemacht werden können. Somit entschieden wir uns für den flexiblen Ansatz AI Funktionalitäten als Microservices zu bauen.
Dieser Ansatz machte es erforderlich, das Aufgabenfeld unserer Data Scientists um Entwicklungsaufgaben zu erweitern. Aufbauend auf den klassischen Aufgaben musste nun jeder Data Scientist in der Lage sein, mit seiner primären Data Science Sprache (R oder Python) eine API (PlumbeR oder FastAPI) für eine einfache Interaktion mit seinem Modell zu entwickeln und diese in einem Docker Container portabel zu machen.

Unsere Integrationslösung: Die Bereitstellung von AI Modellen in Form von Mikro-Services.
Ausgerüstet mit diesem Wissen sind die Data Scientists nun nicht nur in der Lage, fertig trainierte Modelle zur Verfügung zu stellen. Sie sind nun auch in der Lage, sämtliche hierfür erforderlichen Schritte in einzelnen Tasks zu automatisierbaren Pipelines zu transferieren. Damit ist es möglich, einzelne Schritte wie z.B. Retrainings von Modellen oder die Erkennung von Data sowie Concept Drifts automatisiert zu erkennen.
Wichtig dabei zu erwähnen ist, dass neue Data Scientists bei uns im Team gezielt im Zuge des Onbardings auf diese Technologien eingeschult werden.
Wie würde ein Data Scientist seine Arbeit im AI Team beschreiben?
Fragen wir einfach Daniel. Daniel ist Data Scientist im AI Team und hat die Entwicklung der Rolle im Team von Anfang an miterlebt. Wie es ihm geht könnt ihr in folgendem Statement lesen:
“Einer der besten Aspekte als Data Scientist im AI Team ist es, das Privileg zu besitzen meine Arbeit sehr autark gestalten zu können. Nachdem ein Projektziel ausreichend spezifiert wurde, liegt es an uns Data Scientists mit viel Kreativität und dem richtigen Fachwissen ein bestimmtes Machine Learning Problem zu lösen. Besonders gut gefällt mir hierbei die Research Phase, welche zu Beginn jedes unserer Projekte eingeplant ist. Dadurch bin ich in der Lage mein Wissen in vielen Bereichen wie zum Beispiel Computer Vision, Natural Language Processing (NLP) aber auch bei klassischen ML Modellen immer weiter auszubauen.
Des Weiteren schätze ich den regelmäßigen Wissensaustausch innerhalb unseres Teams, sowie die professionelle Zusammenarbeit mit allen Arbeitskollegen sehr. Hierbei bekommt man immer hilfreiche Tipps und ehrliches Feedback zu seinen Projekten. Der Austausch macht Spaß und die Meinung jedes Einzelnen wird wertgeschätzt. Auch der technische Aspekt meiner Arbeit bereitet mir sehr viel Freude. Wir arbeiten ständig daran soviel Prozessschritte wie möglich mittels Kubeflow Pipelines, Docker, Google Cloud Platform und auf unserem Deep Learning Rig (Codename Rick, ja es gibt auch einen Morty bei uns) zu automatisieren. Zu sehen wie verschiedenste Komponenten (unterschiedliche Programmiersprachen) harmonisch ineinandergreifen und Teil eines großen Ganzen werden, ist immer wieder ein gutes Gefühl.”
Du bist neugierig geworden?
Wir haben noch viel vor und suchen deshalb als Unterstützung Menschen, mit ihrer Persönlichkeit und ihren Fähigkeiten sowie ihrem Mut Neues zu lernen und dem Willen mitgestalten zu wollen. Wir freuen uns darauf, dich bei einem persönlichen Gespräch kennen zu lernen.
Weitere interessante Artikel
Du möchtest auch die weiteren Teile dieser AI-Miniserie lesen? Dann haben wir hier die Übersicht für dich:
* English version to be found here.